![]()
A modular, open-source search engine for our world.
Pelias is a geocoder powered completely by open data, available freely to everyone.



Local Installation · Cloud Webservice · Documentation · Community Chat
What is Pelias?
Pelias is a search engine for places worldwide, powered by open data. It turns addresses and place names into geographic coordinates, and turns geographic coordinates into places and addresses. With Pelias, you’re able to turn your users’ place searches into actionable geodata and transform your geodata into real places.
We think open data, open source, and open strategy win over proprietary solutions at any part of the stack and we want to ensure the services we offer are in line with that vision. We believe that an open geocoder improves over the long-term only if the community can incorporate truly representative local knowledge.
Pelias
A modular, open-source geocoder built on top of Elasticsearch for fast and accurate global search.
What's a geocoder do anyway?
Geocoding is the process of taking input text, such as an address or the name of a place, and returning a latitude/longitude location on the Earth's surface for that place.
... and a reverse geocoder, what's that?
Reverse geocoding is the opposite: returning a list of places near a given latitude/longitude point.
What are the most interesting features of Pelias?
- Completely open-source and MIT licensed
- A powerful data import architecture: Pelias supports many open-data projects out of the box but also works great with private data
- Support for searching and displaying results in many languages
- Fast and accurate autocomplete for user-facing geocoding
- Support for many result types: addresses, venues, cities, countries, and more
- Modular design, so you don't need to be an expert in everything to make changes
- Easy installation with minimal external dependencies
What are the main goals of the Pelias project?
- Provide accurate search results
- Work equally well for a small city and the entire planet
- Be highly configurable, so different use cases can be handled easily and efficiently
- Provide a friendly, welcoming, helpful community that takes input from people all over the world
Where did Pelias come from?
Pelias is maintained and developed by Geocode Earth, with a community of business and individual contributors. The project began as part of Mapzen and has been maintained by the same core team since 2013.
How does it work?
Magic! (Just kidding) Like any geocoder, Pelias combines full text search techniques with knowledge of geography to quickly search over many millions of records, each representing some sort of location on Earth.
The Pelias architecture has three main components and several smaller pieces.
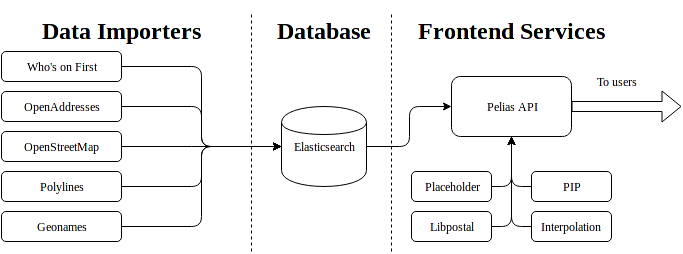
Data importers
The importers filter, normalize, and ingest geographic datasets into the Pelias database. Currently there are six officially supported importers:
- OpenStreetMap: supports importing nodes, ways and relations from OpenStreetMap
- OpenAddresses: supports importing the hundreds of millions of global addresses collected from various authoritative government sources by OpenAddresses
- Who's on First: supports importing admin areas and venues from Who's on First
- Geonames: supports importing admin records and venues from Geonames
- Polylines: supports any data in the Google Polyline format. It's mainly used to import roads from OpenStreetMap
- CSV: supports importing any data in CSV format, which is great for custom data or proprietary data
We are always discussing supporting additional datasets. Pelias users can also write their own importers, for example to import proprietary data into your own instance of Pelias.
Database
The underlying datastore that does most of the query heavy-lifting and powers our search results. We use Elasticsearch. Currently versions 7 and 8 are supported.
We've built a tool called pelias-schema that sets up Elasticsearch indices properly for Pelias.
Frontend services
This is where the actual geocoding process happens, and includes the components that users interact with when performing geocoding queries. The services are:
- API: The API service defines the Pelias API, and talks to Elasticsearch or other services as needed to perform queries.
- Placeholder: A service built specifically to capture the relationship between administrative areas (a catch-all term meaning anything like a city, state, country, etc). Elasticsearch does not handle relational data very well, so we built Placeholder specifically to manage this piece.
- PIP: For reverse geocoding, it's important to be able to perform point-in-polygon(PIP) calculations quickly. The PIP service is is very good at quickly determining which admin area polygons a given point lies in.
- Libpostal: Pelias uses the libpostal project for parsing addresses using the power of machine learning. We use a Go service built by the Who's on First team to make this happen quickly and efficiently.
- Interpolation: This service knows all about addresses and streets. With that knowledge, it is able to supplement the known addresses that are stored directly in Elasticsearch and return fairly accurate estimated address results for many more queries than would otherwise be possible.
Dependencies
These are software projects that are not used directly but are used by other components of Pelias.
There are lots of these, but here are some important ones:
- model: provide a single library for creating documents that fit the Pelias Elasticsearch schema. This is a core component of our flexible importer architecture
- wof-admin-lookup: A library for performing administrative lookup using point-in-polygon math. Previously included in each of the importers but now only used by the PIP service.
- query: This is where most of our actual Elasticsearch query generation happens.
- config: Pelias is very configurable, and all of it is driven from a single JSON file which we call
pelias.json. This package provides a library for reading, validating, and working with this configuration. It is used by almost every other Pelias component - dbclient: A Node.js stream library for quickly and efficiently importing records into Elasticsearch
Helpful tools
Finally, while not part of Pelias proper, we have built several useful tools for working with and testing Pelias
Notable examples include:
- acceptance-tests: A Node.js command line tool for testing a full planet build of Pelias and ensuring everything works. Familiarity with this tool is very important for ensuring Pelias is working. It supports all Pelias features and has special facilities for testing autocomplete queries.
- compare: A web-based tool for comparing different instances of Pelias (for example a production and staging environment). We have a reference instance at pelias.github.io/compare/
- dashboard: Another web-based tool for providing statistics about the contents of a Pelias Elasticsearch index such as import speed, number of total records, and a breakdown of records of various types.
Documentation
The main documentation lives in the pelias/documentation repository.
Additionally, the README file in each of the component repositories listed above provides more detail on that piece.
Here's an example API response for a reverse geocoding query
```javascript $ curl -s "search.mapzen.com/v1/reverse?size=1&point.lat=40.74358294846026&point.lon=-73.99047374725342&api_key={YOUR_API_KEY}" | json { "geocoding": { "attribution": "https://search.mapzen.com/v1/attribution", "engine": { "author": "Mapzen", "name": "Pelias", "version": "1.0" }, "query": { "boundary.circle.lat": 40.74358294846026, "boundary.circle.lon": -73.99047374725342, "boundary.circle.radius": 500, "point.lat": 40.74358294846026, "point.lon": -73.99047374725342, "private": false, "querySize": 1, "size": 1 }, "timestamp": 1460736907438, "version": "0.1" }, "type": "FeatureCollection", "features": [ { "geometry": { "coordinates": [ -73.99051, 40.74361 ], "type": "Point" }, "properties": { "borough": "Manhattan", "borough_gid": "whosonfirst:borough:421205771", "confidence": 0.9, "country": "United States", "country_a": "USA", "country_gid": "whosonfirst:country:85633793", "county": "New York County", "county_gid": "whosonfirst:county:102081863", "distance": 0.004, "gid": "geonames:venue:9851011", "id": "9851011", "label": "Arlington, Manhattan, NY, USA", "layer": "venue", "locality": "New York", "locality_gid": "whosonfirst:locality:85977539", "name": "Arlington", "neighbourhood": "Flatiron District", "neighbourhood_gid": "whosonfirst:neighbourhood:85869245", "region": "New York", "region_a": "NY", "region_gid": "whosonfirst:region:85688543", "source": "geonames" }, "type": "Feature" } ], "bbox": [ -73.99051, 40.74361, -73.99051, 40.74361 ] } ```How can I install my own instance of Pelias?
To try out Pelias quickly, use our Docker setup. It uses Docker and docker-compose to allow you to quickly set up a Pelias instance for a small area (by default Portland, Oregon) in under 30 minutes.
Do you offer a free geocoding API?
Pelias itself does not have API keys and is software you can run freely yourself.
However, for those looking for a hosted option, you can sign up for an API key at Geocode Earth. Geocode Earth is a geocoding service with Pelias at its core, created by the maintainers of Pelias. Combined with our experience hosting Mapzen Search, we've been running geocoding services since 2014.
Discounts and free plans are available for academic and open-source software projects.
What's it built with?
Pelias itself (the import pipelines and API) is written in Node.js, which makes it highly accessible for other developers and performant under heavy I/O. It aims to be modular and is distributed across a number of Node packages, each with its own repository under the Pelias GitHub organization.
For a select few components that have performance requirements that Node.js cannot meet, we prefer to write things in Go. A good example of this is the pbf2json tool that quickly converts OSM PBF files to JSON for our OSM importer.
Elasticsearch is our datastore of choice because of its unparalleled full text search functionality, scalability, and sufficiently robust geospatial support.
Contributing
We built Pelias as an open source project not just because we believe that users should be able to view and play with the source code of tools they use, but because real, local knowledge is key for any global geospatial project.
Reports on what works and what doesn't, especially if it contains unique local knowledge are extremely helpful. Be sure to follow the issue templates so the team has everything we need to know to address the issue in the future.
Pull requests that fix small issues, improve performance, fix typos, etc are always welcome.
Pull requests for larger issues are of course great too, but we really recommend you reach out to the core team before you start doing that work. Pelias is a complex project. We find that unexpected large pull requests often have downsides or conflicts with our future roadmap that means they can never be merged. We want to make sure this doesn't happen to you!
AI Contribution Guidelines
The Pelias Core team sparingly, carefully and judiciously uses AI tools to improve the project. We don't mind if you use AI similarly to help you contribute, as long as you disclose it.
However, issues or pull requests generated primarily by AI with little human input are not welcome.
Contributions made completely by AI have essentially no value and do nothing but create noise and errors to be discovered and solved. Keep in mind the core team also has access to AI tools. So if your idea of helping is to one shot "build feature X for Pelias" and then send it to us, we could have done the same, except we also have experience and knowledge of our roadmap, what works, what doesn't, etc.
The generation of code and issue descriptions is not the bottleneck for improvement of Pelias. Instead, it's the ability to reliably evaluate changes to make sure they push the project towards higher quality. This is the part where you and the core team, as humans can contribute more than AI ever could.
We expect that anyone contributing to Pelias has a high level of understanding of the changes they are proposing.
In particular, we recommend you don't use AI to write massive pull request or issue descriptions. AI written text is usually verbose and full of hard to spot errors or irrelevant info. We'd prefer something written by you, even if it's imperfect in its own way.
Pelias Core team
The current Pelias team can be found on Github as missinglink and orangejulius.
To reach out to the core team in private, you can email us at team@pelias.io.
Members emeritus include: